|
I am an applied research scientist and a team lead at Lunit. My team is responsible for building biomedical foundation models and next generation services at Lunit. Currently, my team is building clinical domain specialized agents and services. In summer of 2021, I defended my PhD in Computer Science at Johns Hopkins University where I developed deep learning models for recognizing fine-grained interactions from videos with my primary advisor Prof. Gregory Hager . I also worked closely with Prof. Alan Yuille and Austin Reiter. I received both B.S and M.S.E in computer science from JHU. I am from Seoul, Korea and I enjoy playing golf. I also served as the 9-th president of the Korean Graduate Student Association at JHU. CV / Google Scholar / Github |

|
|
|
|
Much of my research is about fine-grained recognition, learning with little to no labeled data, foundation models in the biomedical domain. Currently, I am most excited about building clinical domain specialized agents and services. |
|
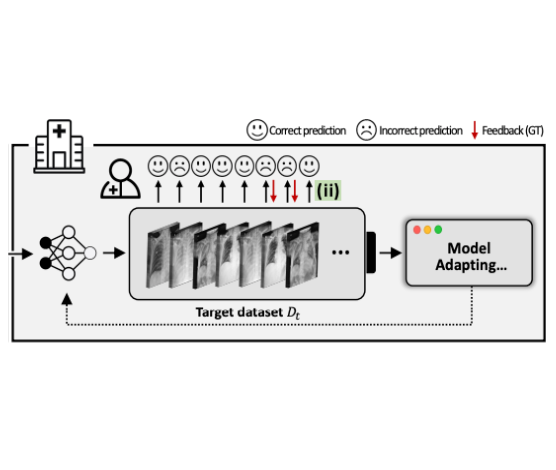
Junha Song, Tae Soo Kim*, Junha Kim, Gunhee Nam, Thijs Kooi ECCV, 2024 Users might be more likely to provide feedback on data points where the model makes incorrect predictions. This paper investigates how to leverage this biased set of samples with user feedback to update model under deployment environment. |
|
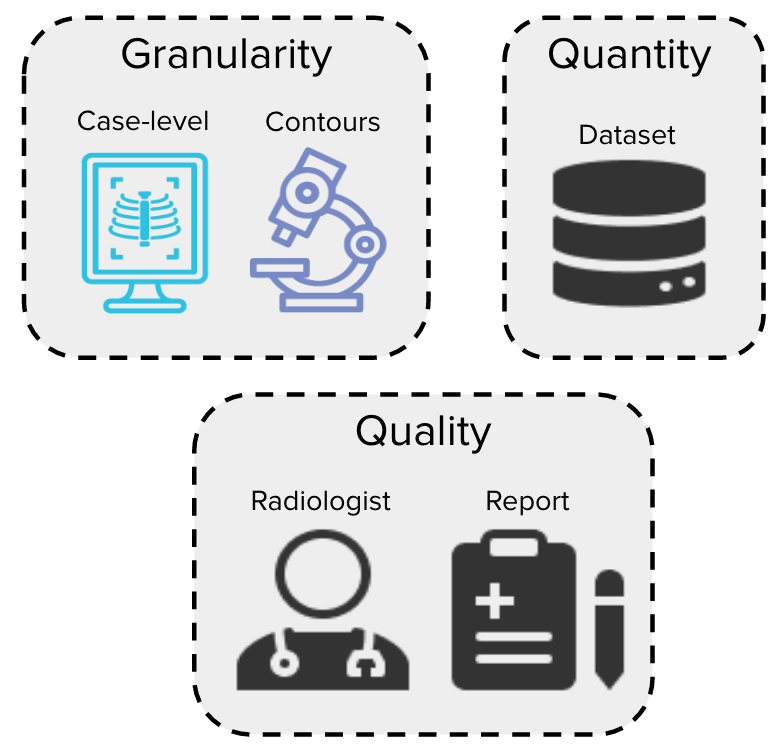
Tae Soo Kim*, Geonwoon Jang*, Sanghyup Lee, Thijs Kooi MICCAI, 2022 Do we really know how much annotated data we need to reach a certain desired computer aided diagnosis (CAD) system performance? We define the cost of building a deep-learning based CAD system with respect to the following three dimensions: Granularity, Quantity and Quality of annotations. We investigate how each dimension ultimately impacts the resulting CAD performance and provide guidance to practitioners on how to optimize for data cost when building CAD systems for chest radiographs. |

|
Sanchit Hira, Digvijay Singh, Tae Soo Kim, Shobhit Gupta, Gregory D. Hager, Shameema Sikder, Swaroop Vedula, Gregory D. Hager IJCARS, 2022 Can deep learning models assess the quality of a surgery directly from a video? We show that our video analysis model can accurately assess surgical skill from real world cataract surgeries. |

|
Tae Soo Kim, Bohoon Shim, Michael Peven, Weichao Qiu, Alan Yuille, Gregory D. Hager WACV-RWS, 2022 / Dataset publicly available here Simulated Articulated VEhicles Dataset (SAVED) is the first dataset of synthetic vehicles with moveable parts. Using SAVED, we show that we can train a model with synthetic images to recognize fine-grained vehicle parts and orientation directly from real images. |
|
Tae Soo Kim, Jonathan Jones, Gregory D. Hager ICCV, 2021 Do current video models have the ability to recognize an unseen instantiation of an interaction defined using a combination of seen components? We show that it ispossible by specifying the dynamic structure of an action using a sequence of object detections in a top-down fashion. When the top-down structure is combined with a dual-pathway bottom-up approach, we show that the model can then generalize even to unseen interactions. |

|
Tae Soo Kim*, Jonathan Jones*, Michael Peven*, Zihao Xiao, Jin Bai, Yi Zhang, Weichao Qiu, Alan Yuille, Gregory D. Hager AAAI, 2021 video This compositional approach allows us to reframe fine-grained recognition as zero-shot activity recognition, where a detector is composed “on the fly” from simple first-principles state machines supported by deep-learned components. Listen to Dr. Alan Yuille talk about this work here (from 15:00 and on)! |

|
Tae Soo Kim, Yi Zhang, Zihao Xiao, Michael Peven, Weichao Qiu, Jin Bai, Alan Yuille, Gregory D. Hager arxiv, 2019 SAFER models a large space of fine-grained activities using a small set of detectable entities and their interactions. Such a design scales effectively with concurrent developments of object detectors, parsers and more. Our model effectively detects fine-grained human activities without any activity level supervision in video surveillance applications. |

|
Tae Soo Kim, Michael Peven, Weichao Qiu, Alan Yuille, Gregory D. Hager WACV-W, 2019 Recent deep neural network based computer vision models can be trained to recognize pretty much anything given enough data. We show we can synthesize visual attributes using the UnrealEngine4 to train activity classification models. |

|
Tae Soo Kim*, Felix Yu*, Gianluca Silva Croso*, Ziang Song, Felix Parker, Gregory D. Hager, Austin Reiter, Swaroop Vedula, Haider Ali, Shameema Sikder JAMA Network Open, 2019 Competence in cataract surgery is a public health necessity, and videos of cataract surgery are routinely available to educators and trainees but currently are of limited use in training. We develop tools that efficiently segment videos of cataract surgery into constituent phases for subsequent automated skill assessment and feedback. |
|
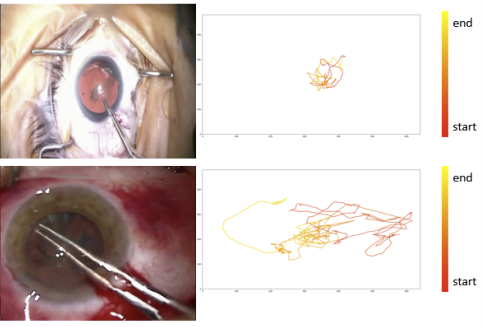
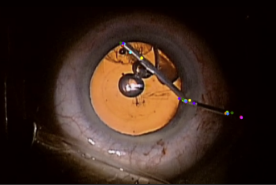
Tae Soo Kim, Molly O'Brien, Sidra Zafar, Anand Malpani, Gregory D. Hager, Shameema Sikder, Swaroop Vedula IJCARS, 2019 We introduce a model for objective assessment of surgical skill from videos of microscopic cataract surgery. Our model can accurately predict surgeon's skill level from tool tip movements captured in the surgical view. |
|
Tae Soo Kim, Anand Malpani, Austin Reiter, Gregory D. Hager, Shameema Sikder, Swaroop Vedula MICCAI-W, 2018 We evaluate reliability and validity of crowdsourced annotations for information on surgical instruments (name of instruments and pixel location of key points on instruments) in cataract surgery. |

|
Weichao Qiu, Fangwei Zhong, Yi Zhang, Siyuan Qiao, Zihao Xiao, Tae Soo Kim, Yizhou Wang, Alan Yuille ACM-MM, 2017 UnrealCV is an open source project to help computer vision researchers build virtual worlds using Unreal Engine 4 (UE4). Check it out here. |
|
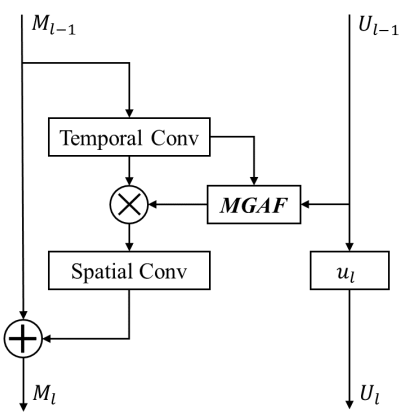
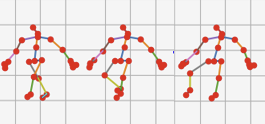
Tae Soo Kim, Austin Reiter CVPR-W, 2017 We re-design the TCN with interpretability in mind and take a step towards a spatio-temporal model that is easier to understand, explain and interpret. |
|
|
 |
Reviewer, CVPR, ICCV, ECCV
Reviewer, AAAI Reviewer, MICCAI, IPCAI |
|
|
|

|
Head Teaching Assistant for EN.600.661, Computer Vision. Fall 2015, Fall 2016
Head Teaching Assistant for EN.600.684, Augmented Reality. Spring 2016 Head Teaching Assistant for EN.600.107, Introductory Programming in Java. Summer 2015 Head Teaching Assistant for EN.600.226, Data Structures. Spring 2015 |
|
Website template credits
|